Overview
Data science and DevOps teams deal with greater complexity, larger compute costs, and higher latency when trying to leverage large deep learning models like BERT, T5, and GPT. It is neither cheap nor easy to optimize or fine-tune such models. To address this problem, Stochastic X and Amazon SageMaker are both great options that help engineers achieve their machine learning model fine-tuning needs. In this article, we conduct an experiment to compare key model latency and performance measures between Stochastic X and SageMaker to determine which product is more cost-efficient and allows you to run more inferences on what you pay for.
Disclaimer: Measurements conducted in this comparison do not account for network latencies.
Stochastic X
Stochastic is a company that spun out of Harvard computer science and electrical engineering research. The founders created Stochastic to help companies and engineers deploy state-of-the-art AI through their AI acceleration platform, Stochastic X. Stochastic automates the time-consuming and complex process of model compression and optimization for ready-to-deploy or already deployed models.
Stochastic's software integrates state-of-the-art ML techniques that allows teams to skip tedious experiments for optimizing models, thus reducing time to production from months to hours. The result is more models on fewer computers and reduced cloud expenses with lower latency by compressing larger models to be smaller than their smaller, non-compressed counterparts.
Amazon SageMaker
SageMaker is Amazon's fully managed machine learning service. With SageMaker, data scientists and developers can build and train machine learning models, and then directly deploy them into a production-ready hosted environment. SageMaker provides common machine learning algorithms that are optimized to run efficiently against extremely large data in a distributed environment.
SageMaker offers flexible distributed training options that adjust to your specific workflows. You can deploy a model into a secure and scalable environment from SageMaker Studio or the SageMaker console. Training and hosting are billed by minutes of usage, with no minimum fees and no upfront commitments.
The Experiment
To compare Amazon SageMaker to Stochastic X, we used benchmarks to compare model latency. Model latency is the time it takes for a model to process the input, which gives us two key calculations that help us compare SageMaker to Stochastic X:
Throughput: number of inferences that can be done in 1 second.
Inferences/$: number of inferences that can be done with 1 dollar. It is calculated using the throughput and the price of the virtual machine.
To run these benchmarks, we used a g4dn.xlarge machine from AWS. This machine has a T4 GPU with 16 GB of RAM. Other important specifications are:
Operative system: Linux - Ubuntu 20.04
Architecture: x86_64
CPU: Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz
CPU RAM memory: 16 GB
Machine price(g4dn.xlarge): $0.526
Machine price if used in SageMaker (ml.g4dn.xlarge 4 vCPU, 16 GiB): $0.7364
Random inputs were created for the benchmark, so there was no specific dataset used. Before running the benchmark, we warmed up to prepare the GPU, which consisted of feeding the input several times before starting to measure times. The input was fed 10 times as a warmup before starting measurements were conducted. After completing this warmup, the inputs were fed and latencies were measured 10 times. We used the median latency time for this comparison, and calculated our results.
Results
After running our tests, we conclude with two kinds of optimizations:
Optimizations that do not reduce the accuracy of the model: the average speedup that we found was around 4.6x
Optimizations that reduce the accuracy of the model: the average speedup that we got was around 7.7x
Other important notes:
The accuracy reduction of some optimization techniques depends on the task type and the model. For example, for the RoBERTa model and sequence classification task, the accuracy is only reduced by 1.33%
The higher the batch size and the sequence length, the higher the speedup
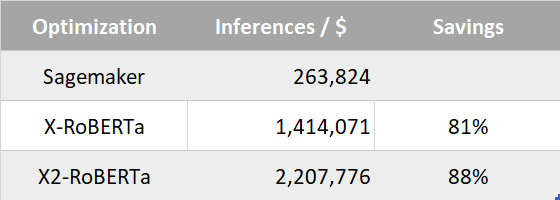
This table below shows how Stochastic's AI Acceleration Platform compares against SageMaker when it comes to inferences per dollar and savings.
Conclusions
After conducting our experiment, the most cost-efficient product is Stochastic X. Not only does Stochastic X reduce times faster than SageMaker, it is also cheaper. Using Stochastic results in better savings and more inferences than Amazon’s SageMaker.
View more from results from our experiment in this table below:
Sign up to get early access to Stochastic X here.