
When it comes to model benchmarking and building AI products, you may be used to asking these following questions.
What is the problem we are trying to solve?
What are the specific requirements and constraints of the problem, such as the input data format, output data format, and processing time?
What are the appropriate evaluation metrics for the problem?
How do you ensure that the model is reliable, interpretable, and maintainable over time?
The vast and diverse applications of AI in the real world require that every model be evaluated differently - this keeps model benchmarking fair. When you build models you may initially only think about accuracy but when you build products, the model latency and serving cost also become very important factors. From a product standpoint, all these questions tend to boil down to these four core requirements about your AI model:
Accuracy
Latency performance
Cost effectiveness
And how these three interact as you scale up your model
The balancing act between these requirements becomes extremely important as you’re building products. However, that’s hard to do right now. There are so many different configurations of hardware, batch size, sequence length, and evaluation metrics for the different applications and models. It’s extremely difficult to efficiently experiment with these variables to see which configurations can best meet the goals of the user. Unlike traditional software, the optimization of AI models currently requires interconnected DevOps optimizations to achieve full benefits. Ultimately, this is a headache for data science and dev ops teams as there are so many different permutations and configurations of optimization, hardware, and deployment options to consider when optimizing models. Not to mention how maintaining accuracy for these large transformer models, such as BERT, T5 and GPT, may already be hard enough for many folks.
Currently, most people have to sequentially run experiments on many different combinations of model optimizations and hardware until they find one that fits their needs. The lack of existing tools and resources to benchmark such optimizations for training and deploying models, results in a highly manual, technically difficult, and time-consuming process.
To solve this, the Stochastic platform allows you to easily control how much the optimization process weighs the four core requirements - accuracy, latency, cost, and scalability - for your specific use case of the model. We offer a slide and scale system between the four core needs which you can input how much you prioritize each of the requirements. Once inputted, our algorithm will automatically find the best combination of model optimization, hardware, and deployment options for your model - based on how you prioritize your four core needs. You are also given the extra flexibility to compare multiple options. This allows you to see the benchmark results real time during model optimization, cutting down on the traditional long iterative process of experimenting with all the different configurations and optimizations when doing model benchmarking.
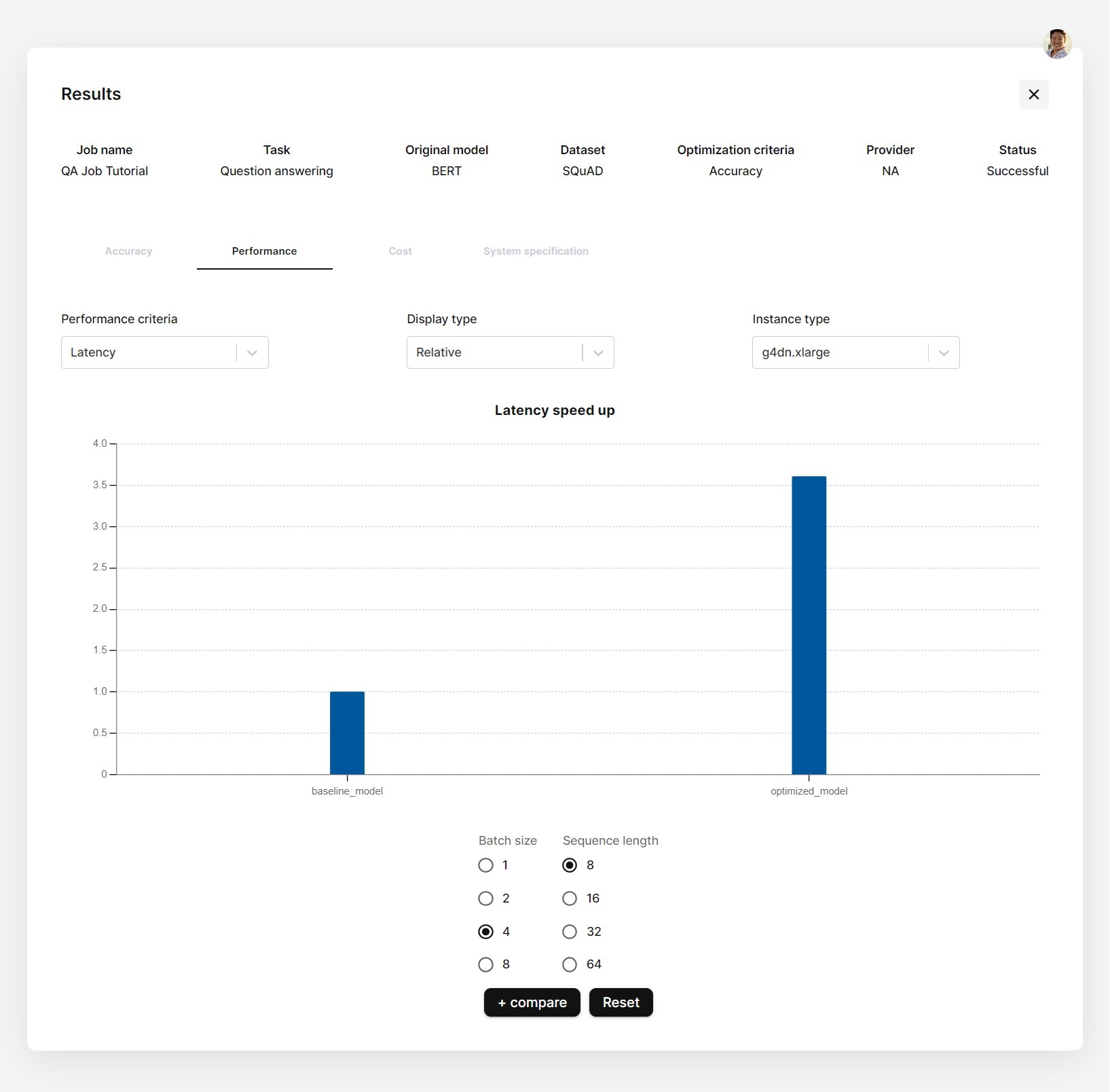

Why is this flexibility important? For example, different applications may have different requirements. In a healthcare setting where accuracy is critical, it may be necessary to sacrifice some cost and latency in order to achieve the highest possible accuracy. On the other hand, in a business setting where cost and speed are more important, it may be necessary to sacrifice some accuracy in order to achieve a more cost-effective and efficient model. Maybe you also want to look at 5 specific types of GPU and CPUs, and see how fast the optimized model behaves with each of them when you scale up your product. Our benchmarking allows you to do all of that and plot how well your models work with different hardware. You can see how much inference/dollar, latency, and accuracy you can get.
To recap for model benchmarking, Stochastic offers:
Inference/dollar and latency benchmarks: This measures the cost-effectiveness and the speed of a model. This helps developers optimize their models for efficiency and reduce the cost of deploying and running them in production.
Model accuracy, precision, and F1 benchmarks: This measures the accuracy of the model's predictions against a set of ground truth labels. This helps developers evaluate the effectiveness of their model.
Memory usage benchmarks: This measures the amount of memory used by the machine learning model during training and inference. This helps developers optimize their model's memory usage.
Hardware performance benchmarks: These platforms measure the performance of the underlying hardware, such as CPUs, GPUs, or TPUs, to help developers understand how their model performs on different hardware configurations.
All in all, Stochastic benchmarking allows you to customize your model’s core needs and find the best optimization for your use case. With Stochastic benchmarking, you can choose and compare the right combination of hardware and software optimizations much easier than ever before.
Does this sound interesting to you? Sign up now for $10 in free credits here